- 數字報

- 小程序

- 公眾號

9月1日,階躍星辰正式發布最強開源端到端語音大模型 Step-Audio 2 mini,該模型在多個國際基準測試集上取得SOTA(State-of-The-Art,即當前最佳水平)成績。在技術層面,Step-Audio 2 mini采用了真正的端到端多模態架構,并將語音理解、音頻推理與生成統一建模,不僅時延更低、輸出更快,還能更加精準地理解副語言信息、非人聲信號等語音要素,顯著提升了語音人機交互的效率和智能上限。目前,Step-Audio 2 mini已經可在GitHub、Hugging Face等平臺下載并體驗。
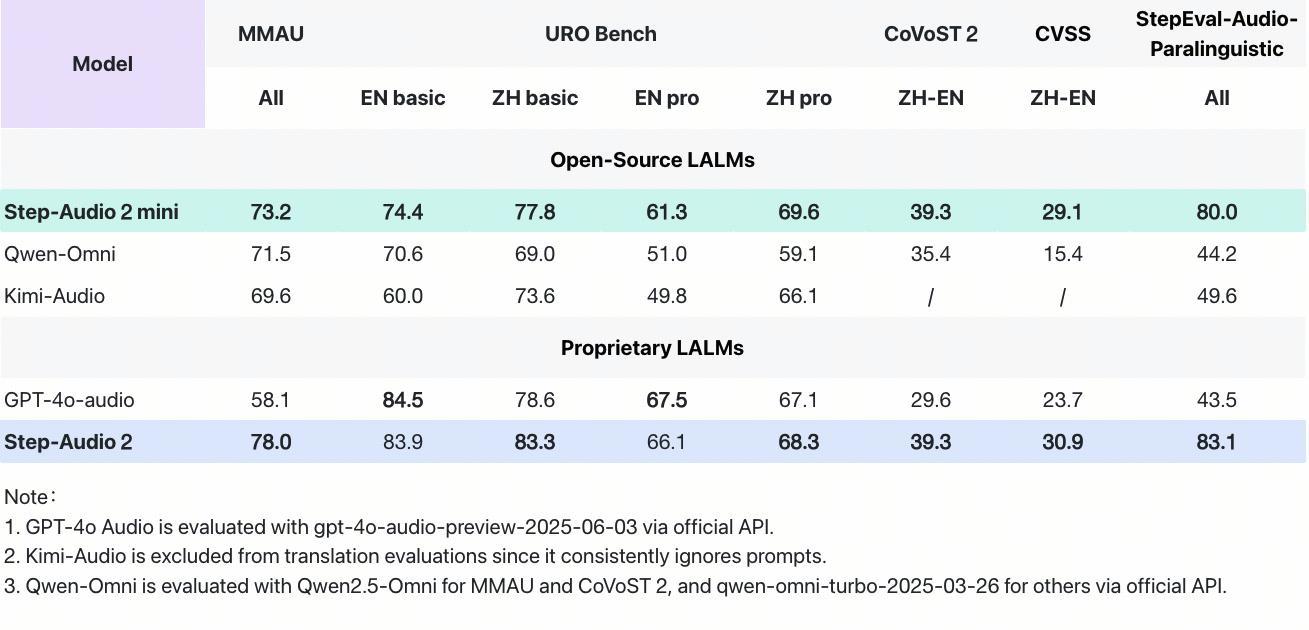
根據測評,這款模型在音頻理解、語音識別、跨語種翻譯、情感與副語言解析、等任務中表現突出,綜合性能超越Qwen-Omni、Kimi-Audio在內的所有開源端到端語音模型,并在大部分任務上超越 GPT-4o-audio。
隨著語音交互成為人機主要交互方式,智能終端設備對語音模型的智商及情商水平提出了更高要求。Step-Audio 2 mini首創了音頻推理能力,能對情緒、語調、音樂等副語言和非語音信號進行精細理解、推理并自然回應,由此讓AI聽懂人類的“弦外之音”;同時,該模型率先支持語音原生的 Tool Calling能力,可實現聯網搜索等操作,有效解決模型幻覺問題,并讓語音模型像文本模型一樣具有更強大的知識儲備和推理能力。
在此之前,吉利發布了搭載階躍星辰端到端語音大模型的吉利銀河 M9,這是行業內端到端語音大模型首次實現量產上車。據階躍星辰相關人士介紹,自去年發布國內首個千億參數端到端語音大模型 Step-1o Audio以來,該公司持續迭代模型性能,并跟吉利、鯨魚機器人、TCL、Cyan青心意創等頭部終端廠商達成深度合作,讓語音大模型在生活場景中為消費者提供更加智能、便捷的互動體驗。
今年以來,階躍星辰已經開源了 8款性能領先的多模態模型,覆蓋語音、視頻生成、圖像編輯、3D、多模態推理等多個類別,為全球開源社區貢獻多模態力量。
友情鏈接: 政府 高新園區合作媒體
Copyright 1999-2025 中國高新網chinahightech.com All Rights Reserved.京ICP備14033264號-5
電信與信息服務業務經營許可證060344號主辦單位:《中國高新技術產業導報》社有限責任公司
